RAG Chat
GitHub Repo (Working Demo)
This is a proof of concept demo I made and presented at Informatics rounds in Nov 2023. It demonstrates the utility of Retrieval Augmented Generation (RAG) in a chat interface as a means of interacting with (in the case of the sample data provided) facilitating interaction with laboratory documentation and residency procedure manuals.
In this demo, the user drag-and-drops a pdf document onto a streamlit app, then also typing in a question. The app then uses the pdf as context to answer the question. The app parses and digests into context that can be provided to the wrapped (openai) LLM model. Results are promising and suggest that RAG could be a useful tool for natural-language “as a database”.
Demo PDF Chat
Two Q&A Samples
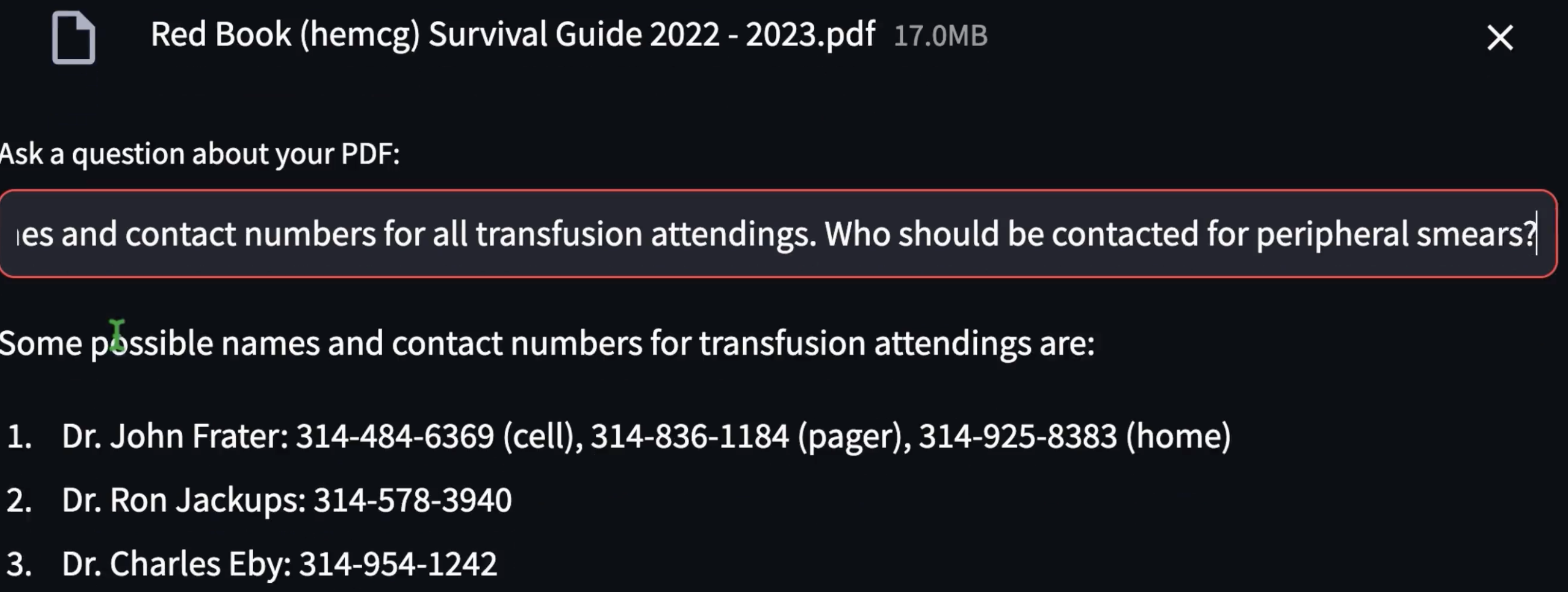
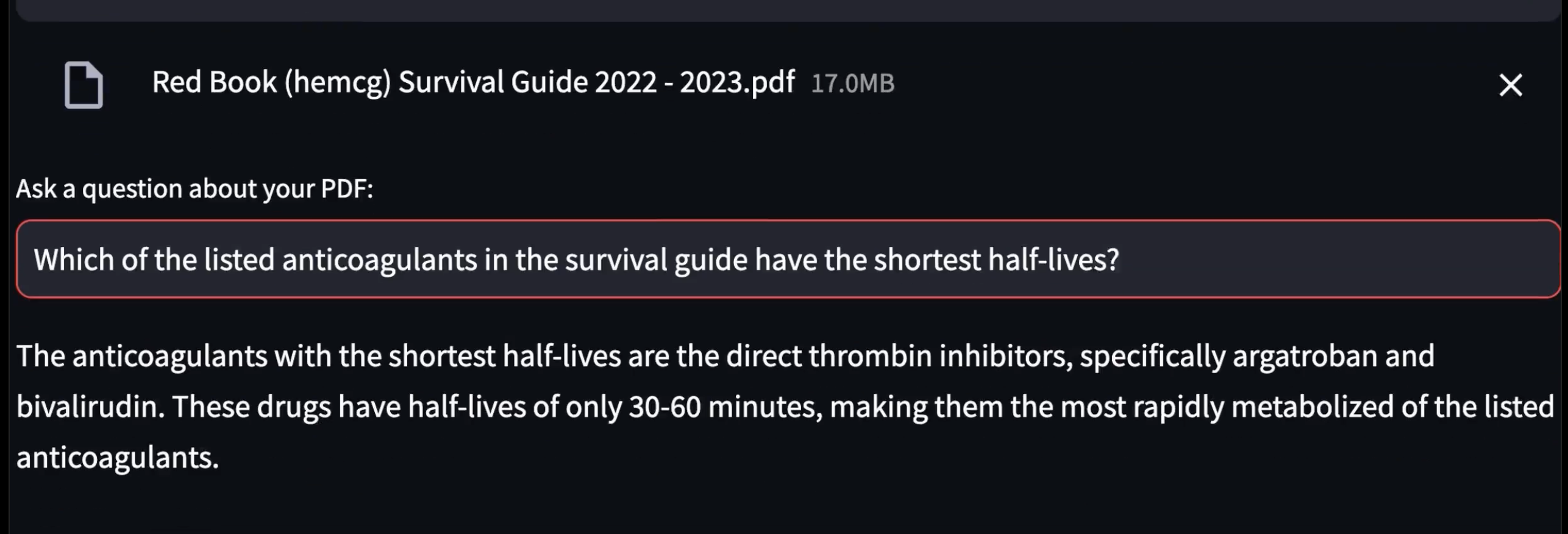

The AI responses are essentially correct. *Note:* In some experiments the AI differentiates between *IV* dabigatran and *oral* dabigatran which is pertinent!, explaining that the oral form has a half-life of 12-17 hours.
Additional Q&A Text Examples
More historical examples of interest can be seen (with explainations of the questions and answers) at github repo above at /_results/sample_qa.md
Background
While foundation Large Language Models (LLMs) excel at a broad range of non-technical domain tasks, they often struggle in deployment in niche (e.g. institution specific) situations as out-of-dataset challenges inevitably arise. The first solution proposed was to “fine-tune” the LLM model: to do the same as in the preparation of the foundation model, but with training data supplemented strategically with specialized task examples.
Interestingly, it was discovered that attention over a crafted context could supplement for training, as data-scientists augmented the language generation process by allowing attention (or at least initialization) over instructive corpora. This represented an interesting paradigm shift as the model itself was always previously–as an identify and a means of training–synonymous with its weights which defined the model. Now, the learned tasks could be augmentated without reference to the parameters at all!
When entire corpora are of relevance in general, one hopes that each individual question only requires a subset of that context that can be retrieved as per relevance to each question, hence Retrieval Augmented Generation (RAG).
By this writing in 2024, chat.openai allows one to upload a pdf (e.g. a resume) and ask questions about it, though no such feature existed at time of the original project summarized here.
This is a working demo of the chat with a pdf feature. It’s purpose was to demonstrate the explore and demonstrate the utility and practicallity of RAG as a novel tool for context-aware language modeling.